Wissen ohne aufwändiges Training verfügbar machen
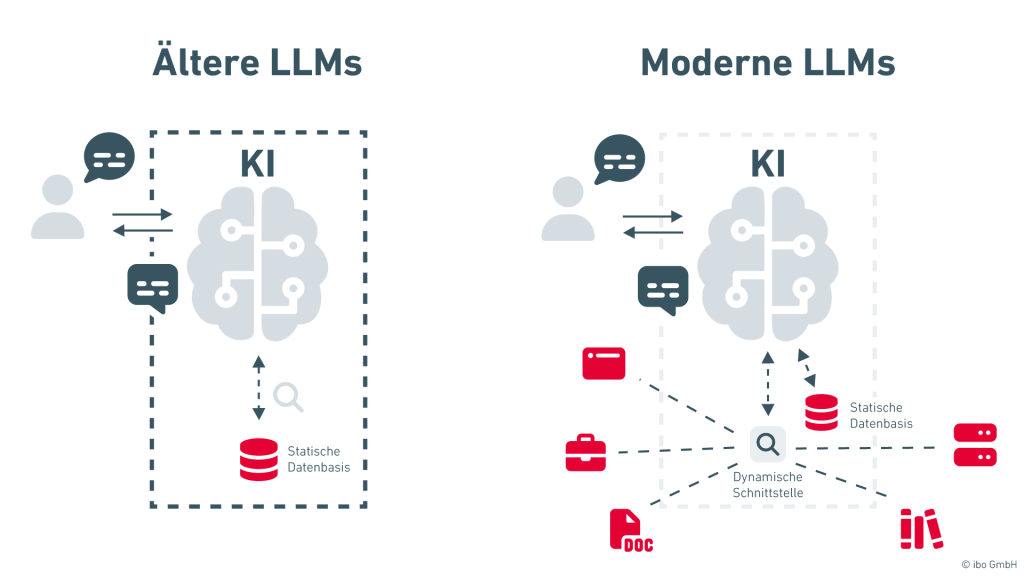
Erinnern Sie sich an die ersten Versionen moderner Large Language Modelle wie ChatGPT oder Claude? Diese Systeme wurden bis zu einem klar definierten Zeitpunkt mit Wissen aus einer Datenbasis gefüttert und trainiert. Fragen zu neueren Entwicklungen konnten sie daher nicht beantworten. Gleichzeitig ist das Training solcher Modelle extrem aufwendig und verursacht Kosten in Millionenhöhe.
Moderne Systeme lösen dieses Problem, indem sie zur Laufzeit auf externe Wissensquellen zugreifen – etwa auf Dokumente, Wikis oder Datenbanken eines Unternehmens. Dieses Wissen wird dabei nicht in das neuronale Netz „hineintrainiert“, sondern über Schnittstellen dynamisch eingebunden.

Warum ist es für ein Unternehmen wichtig auf aktuelle Daten per KI zugreifen zu können?
Wir benötigen jeden Tag neue Informationen. Sei es um sich als neue/neuer Mitarbeiter:in einzuarbeiten oder um als jemand fachfremdes auf prozessabhängige Informationen zuzugreifen. Egal ob es Fragen zu Zuständigkeiten, Prozessen und Abläufen, Mitarbeiterbeschreibungen, Ablageorten oder Dokument-Inhalten sind. Nicht immer kann garantiert werden, dass alle Mitarbeitenden die benötigten unternehmensinternen Daten finden oder gar verstehen.
Mit Unterstützung einer KI, die zuverlässig auf aktuelle Zahlen und Informationen zugreifen kann und diese in eine adäquate Antwort gießt, ist der Arbeitsablauf und der damit einhergehende Aufwand zur Erledigung von Aufgaben spürbar effizienter. Besonders in Hinblick auf die Digitalisierung des Arbeitsplatzes spielt dieses Thema eine zunehmend größere Rolle. Es kann nicht nur wertvolle Zeit eingespart, sondern auch inhaltlichen Missverständnissen vorgebeugt werden. Zudem ist man zum Zeitpunkt der Anfrage an die KI durch die dynamische Schnittstelle immer auf dem neuesten Stand, da auf aktuelle Daten zugegriffen werden können.
Wie ist es also möglich, dass heutige KI-Systeme beispielsweise als Chatbots zuverlässig auf aktuelles Unternehmenswissen zugreifen können?
1. Dokumente zugreifbar machen
Der erste Schritt ist organisatorisch und technisch zugleich: Relevante Dokumente müssen aus ihren Ursprungssystemen erschlossen werden.
Typische Quellen sind:
- Dateiablagen (z. B. PDFs, Office-Dokumente)
- Kollaborationsplattformen
- interne Wissensdatenbanken
Die Inhalte werden extrahiert und in eine einheitliche, maschinenlesbare Form überführt. Häufig werden dabei auch Metadaten wie Autor, Erstellungsdatum oder Zugriffsrechte mitgeführt.
2. Segmentierung (Chunking)
Da Sprachmodelle nur begrenzte Textmengen gleichzeitig verarbeiten können, werden Dokumente in kleinere Abschnitte zerlegt – sogenannte „Chunks“.
Wichtig ist dabei:
- Die Abschnitte sollten in sich semantisch sinnvoll sein
- Typische Größen liegen im Bereich 500 bis 100 Worten (oder technischer „einige hundert Tokens“)
- Leichte Überlappungen helfen, Kontextverluste zu vermeiden
So entstehen handhabbare Informationseinheiten, die später vom KI-System gezielt abgerufen und daraus Antworten generiert werden können.
3. Semantische Repräsentation und Speicherung
Im nächsten Schritt werden die Textabschnitte in sogenannte Embeddings umgewandelt. Dabei handelt es sich um numerische Vektoren, die die inhaltliche Bedeutung eines Textes kodieren.
Dieser Schritt ist für die spätere Identifikation relevanter Informationen wichtig. Während klassische Suchverfahren auf exakten Wortübereinstimmungen (Volltextsuche) basieren, ermöglichen Embeddings eine Suche nach Bedeutung.
Technisch geschieht dies, indem Texte in einem hochdimensionalen Raum repräsentiert werden. Jeder Textabschnitt entspricht dabei einem Punkt in diesem Raum. Inhalte mit ähnlicher Bedeutung liegen nahe beieinander, auch wenn sie unterschiedliche Begriffe verwenden.
In der Anwendungsphase wird eine Suchanfrage ebenfalls in einen solchen Vektor umgewandelt. Anschließend werden diejenigen Textabschnitte gefunden, deren Vektoren sich in räumlicher Nähe befinden – also inhaltlich am besten zur Anfrage passen.
Diese Form der „semantischen Suche“ bildet die Grundlage dafür, dass KI-Systeme nicht nur passende Stichwörter, sondern tatsächlich relevante Inhalte finden und für die Antwortgenerierung nutzen können.
4. Zugriff durch KI-Systeme zur Laufzeit
Nach diesen Ausführungen lässt sich leicht nachvollziehen, was passiert, wenn ein Nutzer eine Frage an die KI stellt:
- Die Anfrage wird in eine semantische Repräsentation überführt
- Das System sucht in der Vektordatenbank nach inhaltlich ähnlichen Textabschnitten
- Die gefundenen Inhalte werden als Kontext an das Sprachmodell übergeben
- Das Modell generiert auf dieser Basis eine fundierte Antwort
Dieses Vorgehen wird als „Retrieval-Augmented Generation“ (RAG) bezeichnet.
Wie geht das in der Praxis?
Wenn ein Unternehmen interne Regelungen, Verfahrensdokumentationen oder Sitzungsprotokolle auswertbar machen möchte, reicht es aus, der KI die entsprechenden Dokumente oder Intranet-Seiten „zu nennen“. Die KI kann diese Quellen dann wie beschrieben segmentieren, semantisch repräsentieren und in ihrer Antwort berücksichtigen.
Auf strukturierte Informationen, die nicht als klassische Dokumente vorliegen – etwa Daten aus Prozessdatenbanken oder Projektmanagement-Software – kann die KI in der Regel nicht direkt zugreifen. Hier muss die Software die Daten über eine standardisierte Schnittstelle bereitstellen (z. B. einen MCP-Server). Hinter den Kulissen werden die Inhalte ebenfalls in geeignete Abschnitte zerlegt, semantisch kodiert und für die Abfrage verfügbar gemacht.
Das bedeutet: Die KI kann alle relevanten Unternehmensinformationen nutzen, unabhängig davon, ob sie ursprünglich als Textdokumente vorliegen oder in Datenbanken verteilt sind – solange von den Software-Systemen ein Zugriff über die gleichen Mechanismen ermöglicht wird.
Moderne Software-Lösungen machen Unternehmenswissen sichtbar
Software-Lösungen, die dieses Verfahren unterstützten, machen externe Wissensquellen für KI-Systeme zugreifbar. Das Unternehmenswissen wird in vier Schritten sichtbar: Dokumente aus Quellen wie Dateiablagen, Kollaborationsplattformen und Wikis werden erschlossen, in sinnvolle Chunks zerlegt; semantisch als Embeddings in einer Vektordatenbank abgespeichert und bei Anfragen in passenden Abschnitte abgerufen und dem Sprachmodell als Kontext übergeben. Unterschiedliche Datenquellen (Dokumente und strukturierte Systeme) können über gemeinsame Schnittstellen angebunden werden. So erhält die KI stets aktuelle, relevante Informationen, reduziert Suchaufwand, beschleunigt Einarbeitung und Prozesse, verhindert Missverständnisse und steigert Effizienz – unabhängig vom ursprünglichen Format, solange standardisierte Zugriffe bestehen.
Mit Softwarelösungen, wie ibo Prometheus, können Sie mithilfe von KI Prozesse effizient modellieren, Unternehmenswissen einfach und verständlich verfügbar machen, die Arbeit im Unternehmen spürbar optimieren und vieles mehr.
Sie suchen ein Prozessmanagement-System, das mithilfe von KI nicht nur
- Vorschläge zur Prozessgestaltung gibt,
- aus Ihren Fließtexten Prozesse generiert,
- Prozessrisiken ermittelt,
- sondern auch das Prozesswissen in der hier beschriebenen Weise Ihren KI-Bots zur Verfügung stellt, unter Berücksichtigung Ihrer Zugriffsrechte?
Wir beantworten gern Ihren Fragen zu ibo Prometheus oder einem unserer anderen Software-Modulen.
Schreiben Sie einen Kommentar oder besuchen eines unserer Live-Info-Webinare.
Zum Autor

„Der intelligente Einsatz von KI löst Probleme, der blinde Einsatz erzeugt neue.“
Wie sind Ihre Erfahrungen mit dem Einsatz von KI in Ihrem Unternehmen?
Dr. Hans-Georg Stambke
Geschäftsführer ibo Software GmbH
FAQ
Theoretisch kann eine KI auf jegliche digitalisierte Daten und Informationsquellen zugreifen, solange sie in einer mit der Schnittstelle verbundenen Datenablage gespeichert und für die KI lesbar sind.
Eine KI kann die Rolle und die Zugriffsberechtigungen vor Ausgabe von Informationen berücksichtigen, wenn es vorher in den in dem jeweiligen Informationsmanagement-Tool eingeschränkt wurde.
Bei der Indexierung der Daten können auch Metadaten (Zeitstempel, Version, Quelle oder Änderungsdatum) erfasst werden, die es der KI ermöglicht, die Aktualität und Relevanz von Informationen einzuschätzen.
In der Retrieval-Augmented Generation (RAG) werden die Antworten der KI konsequent aus den bereit gestellten und zugriffsberechtigten Quellen erstellt. Überdies kann durch striktes Prompting, wie „Antworte nur, wenn belegt ist …“ und die Pflicht zur Quellenangabe die Wahrscheinlichkeit des Halluzinierens der KI minimiert werden.
Weiterführende Inhalte
- KI-Agenten in der Prozessmodellierung
- KI-Governance gestalten, handlungsfähig bleiben
- Aufgabenkatalog mit KI: Weniger Aufwand und mehr Präzision in der Personalbedarfsermittlung
- MCP im Prozessmanagement: Wie das Model Context Protocol KI mit Unternehmenswissen verbindet
- Projektplanung mit KI in ibo netProject: So erstellen Sie tragfähige Projektpläne
Verpassen Sie keinen Artikel und bleiben Sie immer up to date! Jetzt zum ibo-Newsletter anmelden.